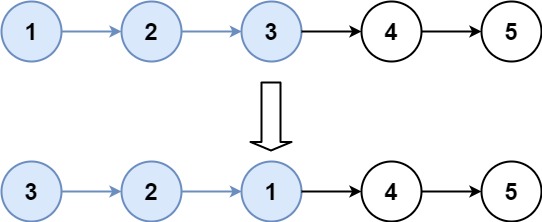
问题描述
给定一个字符串 s 和一个字符串数组 words。 words 中所有字符串 长度相同。
s 中的 串联子串 是指一个包含 words 中所有字符串以任意顺序排列连接起来的子串。
- 例如,如果
words = ["ab","cd","ef"], 那么"abcdef","abefcd","cdabef","cdefab","efabcd", 和"efcdab"都是串联子串。"acdbef"不是串联子串,因为他不是任何words排列的连接。
返回所有串联子串在 s 中的开始索引。你可以以 任意顺序 返回答案。
解题思路
1. 初步理解
首先需要明确,只有当 s 中的某个子串正好由 words 中所有单词组成,并且每个单词出现一次,才符合条件。这提示我们可以使用组合和检查的策略来找到这些子串。
2. 设计策略
基于以上理解,可以采用以下策略:
- 长度计算: 计算
words中所有字符串连接后的总长度,这将是我们在s中搜索的子串的长度。 - 字典统计: 使用一个哈希表(字典)来统计
words数组中每个单词的出现频率。 - 滑动窗口: 在字符串
s上滑动一个固定大小的窗口,并在窗口内部维护一个字典来记录当前窗口中各单词的出现频率。 - 窗口调整: 根据窗口内单词的实际出现情况,调整窗口的开始位置,确保窗口内的单词频率与
words中的单词频率相匹配。
3. 实现细节
- 初始化: 计算每个单词的长度
wordLength,所有单词的数量wordCount,以及应搜索的窗口大小windowSize。 - 遍历: 遍历字符串
s的每个可能的起始位置,步长为wordLength。 - 内部循环: 对每个起始位置,向右滑动窗口,每次移动一个单词的长度,直到窗口尾部超出字符串
s的边界。 - 检查与调整: 每次窗口滑动后,更新当前单词在窗口中的计数,并与
words字典进行比较,如果当前单词计数超过了应有的频率,则调整窗口的左边界,直至窗口内的单词频率再次符合要求。 - 记录结果: 如果窗口大小达到了
windowSize,且窗口内的单词与words中的单词完全匹配,则记录当前窗口的起始位置。
代码实现
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> indices;
if (s.empty() || words.empty())
return indices;
int wordLength = words[0].size();
int wordCount = words.size();
int windowSize = wordLength * wordCount;
if (s.size() < windowSize)
return indices;
// 记录words中每个单词出现的次数
unordered_map<string, int> wordMap;
for (const string& word : words) {
++wordMap[word];
}
// 检查每个可能的开始位置
for (int i = 0; i < wordLength; ++i) {
int left = i;
int right = i;
unordered_map<string, int> currentMap;
while (right + wordLength <= s.size()) {
string word = s.substr(right, wordLength);
right += wordLength;
if (wordMap.find(word) != wordMap.end()) {
++currentMap[word];
// 处理单词出现次数过多的情况
while (currentMap[word] > wordMap[word]) {
string leftWord = s.substr(left, wordLength);
--currentMap[leftWord];
left += wordLength;
}
// 检查是否形成了一个有效的窗口
if (right - left == windowSize) {
indices.push_back(left);
string leftWord = s.substr(left, wordLength);
--currentMap[leftWord];
left += wordLength;
}
} else {
currentMap.clear();
left = right;
}
}
}
return indices;
}
};


![[Open-source tool]Uptime-kuma的簡介和安裝於Ubuntu 22.04系統](https://img-blog.csdnimg.cn/direct/8d0acb2546d94bd4a44bd1a886d80428.png)





![[NSSCTF]-Reverse:[SWPUCTF 2021 新生赛]easyapp(安卓逆向,异或)](https://img-blog.csdnimg.cn/direct/316c18d0c6b44b9fa53015011897a382.png)